Mistral Voxtral Transcribe2, real-time transcription
- Maxime Hiez
- Mistral AI
- 05 Feb, 2026
Introduction
Mistral AI has just unveiled Voxtral Transcribe 2, its second generation of speech transcription models with cutting-edge transcription quality, ultra-low latency and advanced features for professional, production or real-time use.
Introducing Voxtral Transcribe 2
Mistral Voxtral Transcribe 2 is a powerful, fast, and cost-effective family of speech-to-text templates designed to meet the current needs of voice applications : smart meetings, voice assistants, contact centers, live subtitles, regulatory compliance, and more.
This launch includes two complementary models :
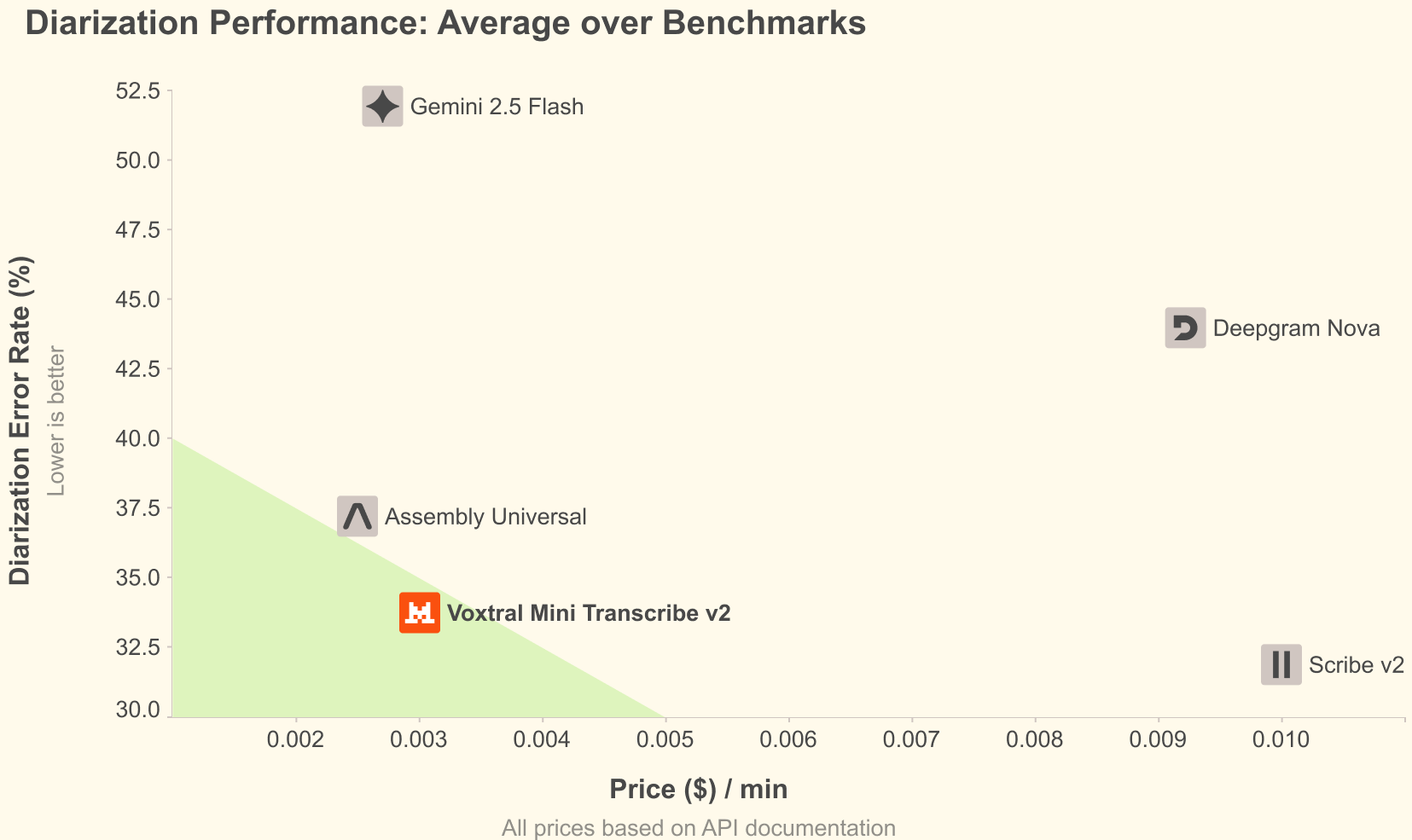
- Voxtral Mini Transcribe V2 : Batch audio processing with advanced features (speaker diarization, timestamps, context bias).
- Voxtral Realtime : Live transcription with configurable latency down to less than 200ms, paving the way for truly natural voice-AI interactions.
Main features
Voxtral Mini Transcribe V2 - Batch transcription
- Ideal for pre-recorded audio files (meetings, interviews, podcasts)
- Speaker diarization : Identifies who is speaking and when
- Word-by-word timestamps : Each word has a precise start / end point
- Context bias : Allows you to specify up to 100 specific characters to improve the recognition of proper nouns or technical terms
- Supports up to 3 hours of audio per request
- Multilingual : Supports 13 languages (English, Chinese, Hindi, Spanish, Arabic, French, Portuguese, Russian, German, Japanese, Korean, Italian, and Dutch)
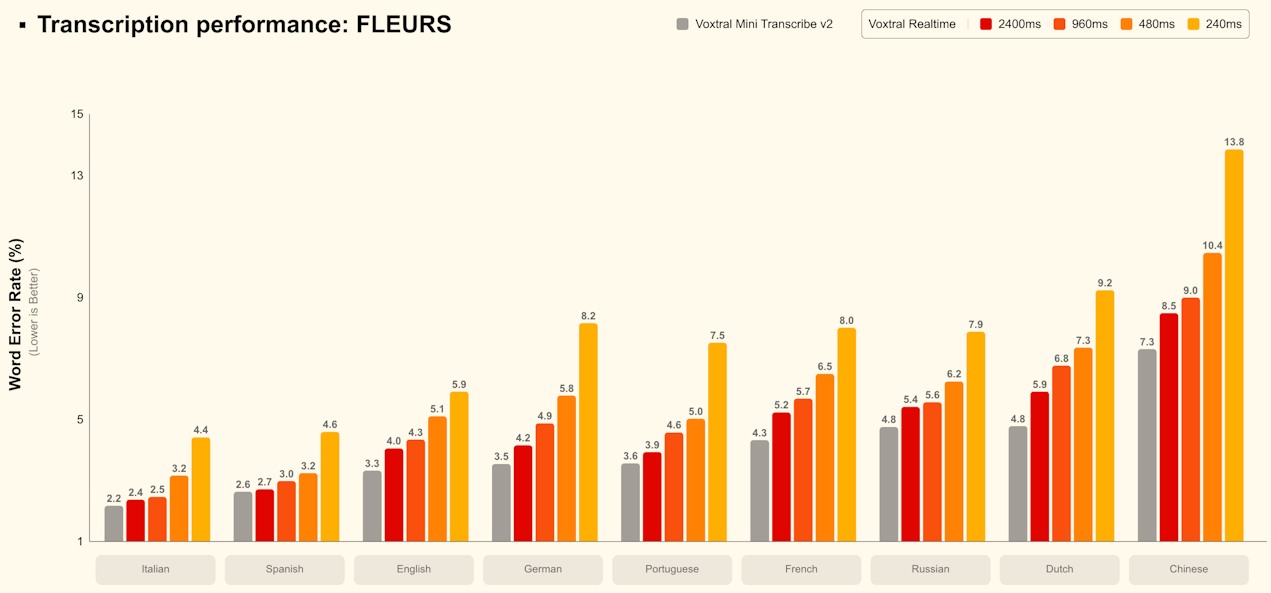
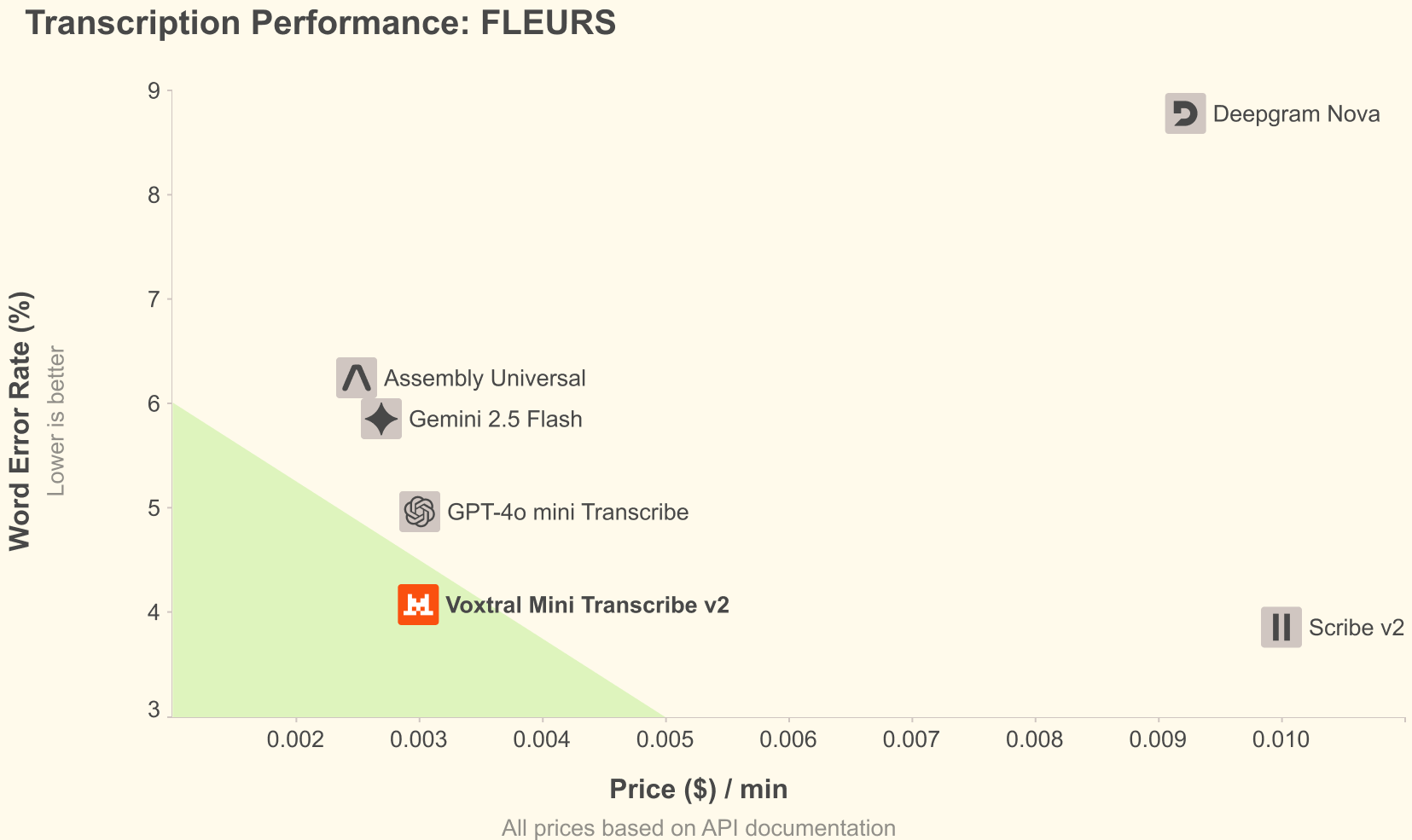
- Price-performance efficiency : ~4% error on the FLEURS benchmark at only 0.003$ per minute, up to 5 times cheaper than major alternatives
Voxtral Realtime - Real-time transcription
- Native streaming architecture : Transcribes audio as it arrives, without artificial slicing
- Configurable latency down to < 200 ms, making transcription virtually instantaneous
- Maintains competitive accuracy even at low latency (1-2% more error compared to the batch model)
- Open-source via Apache 2.0 license : Model sizes available for local or edge deployment
- API available for cloud use
Developer experience and integration
Mistral now offers an audio playground in Mistral Studio, allowing you to :
- Import audio files (.mp3, .wav, .flac, etc.) up to 1GB
- Instantly test the transcription with or without diarization
- Adjust options (timestamps, context bias)
Templates are also accessible via The Chat or directly via API.
Confidentiality and compliance
Both models can be deployed in on-premise or private cloud environments, with configurations compatible with GDPR and HIPAA, a crucial point for uses in health, finance or regulated services.
Professional Use Cases
- Meeting intelligence : Analysis of multilingual meetings with precise attribution of contributions and automatic generation of summaries or reports.
- Voice assistants and Voice Agents : Voice sensors capable of responding or triggering actions with very low latency, perfect for integrated or voice assistants.
- Contact centers : Live call transcription, sentiment analysis, automatic suggestions to agents, and real-time data insertion into CRMs.
- Media & subtitles : Automatic generation of multilingual subtitles with reliable timestamps, even in noisy environments.
- Compliance : Monitoring of audio interactions for audits or compliance purposes, with time-stamped and traceable logs.
Conclusion
Voxtral Transcribe 2 sets a new standard in the speech recognition ecosystem, offering fast, accurate, and cost-effective solutions. With options for batch or real-time processing, and an open-source strategy for use cases requiring confidentiality and control, it’s a crucial component of any modern AI speech platform, while making these capabilities accessible to a wide range of organizations.
Sources
Did you enjoy this post ? If you have any questions, comments or suggestions, please feel free to send me a message from the contact form.
Don’t forget to follow us and share this post.