
Mistral OCR 4, an OCR model for document analysis
- Maxime Hiez
- Mistral AI
- 25 Jun, 2026
Introduction
Mistral AI announced Mistral OCR 4 on June 23, 2026, its next-generation optical character recognition model. The model introduces bounding boxes, typed block classification, and confidence scores per word and per page. It supports 170 languages and can be deployed on-premises for environments with strict data privacy requirements.
Check the Mistral OCR 3 article HERE.
What changes with OCR 4
OCR 4 introduces three new capabilities compared to previous versions :
- Bounding boxes : Precise text localization within the document for custom downstream processing.
- Block classification : Automatic identification of each block type, titles, tables, equations, and signatures.
- Confidence scores : Per-page and per-word scores to drive targeted human verification workflows.
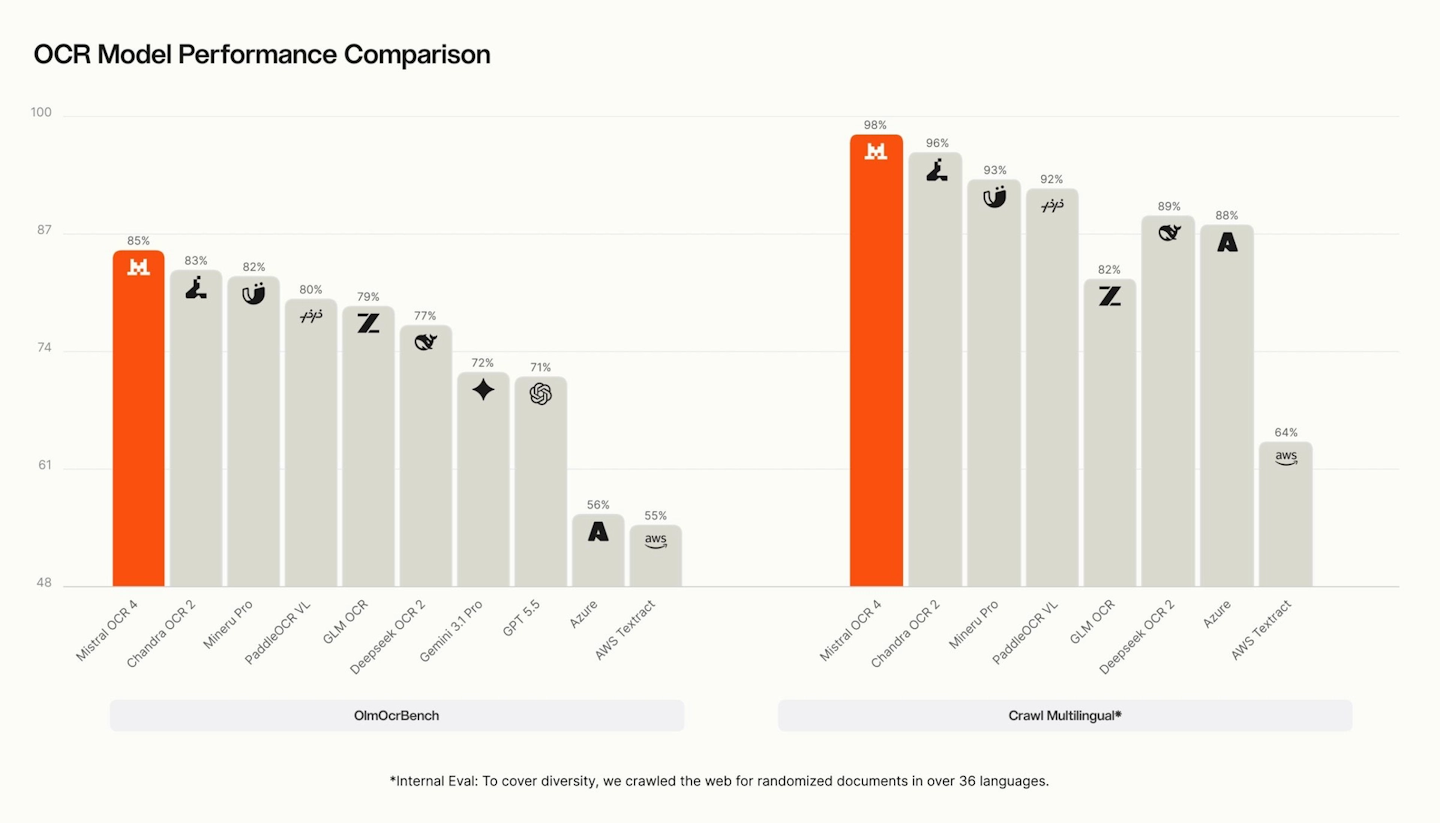
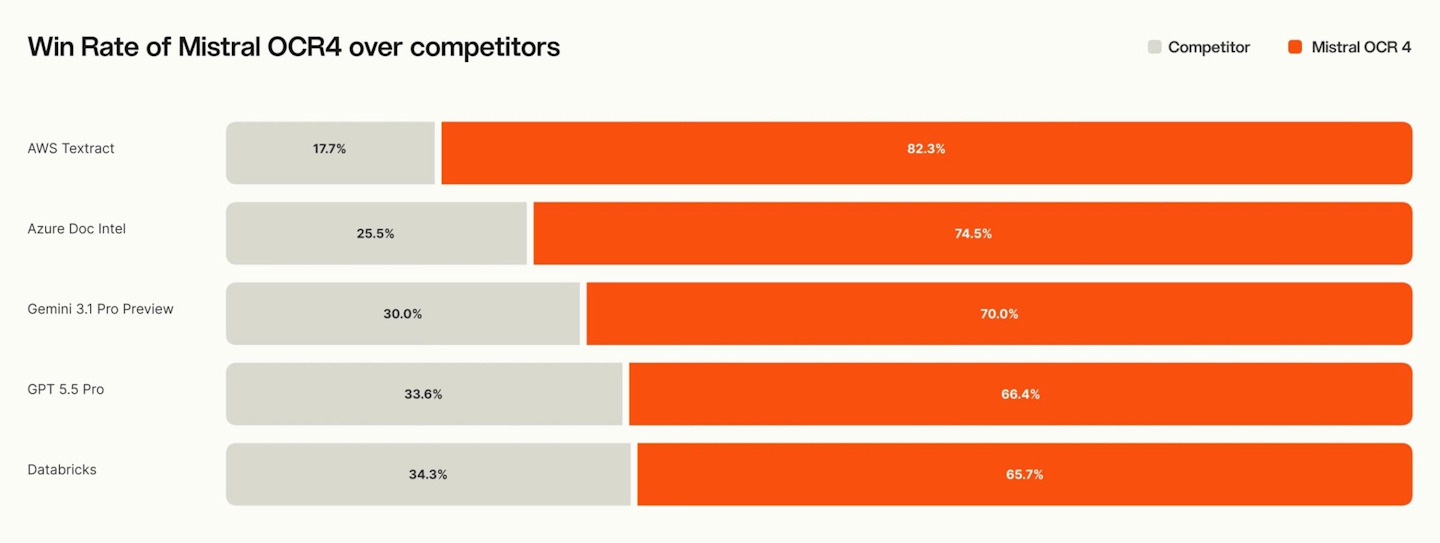
Supported formats are PDF, DOC, PPT, and OpenDocument. On reference evaluations, OCR 4 sets new records : 85.20 on OlmOCRBench and 93.07 on OmniDocBench. A human preference evaluation conducted on over 600 documents across 12 languages reveals an average win rate of 72% against competing systems.
Integration modes
OCR 4 is accessible through two approaches :
- Pure extraction : Direct access to bounding boxes, block types, and confidence scores for custom downstream logic.
- Document AI : Adds JSON schema structuring, image annotation, and custom prompts for business use cases without development.
The model is also integrated with the Mistral Search Toolkit for structured document search and RAG pipelines.
Pricing and availability
OCR 4 is available under three pricing models :
- API : 4$ / 1 000 pages
- Batch API : –50% at 2$ / 1 000 pages
- Document AI : 5$ / 1 000 pages
OCR 4 is available via :
- Mistral API and Mistral Studio : Direct access as of June 23, 2026
- Amazon SageMaker : Available on the Marketplace
- Microsoft Foundry : Integration available
- Snowflake : Parse Document integration in rollout
- Self-hosting : Option available for environments with data privacy constraints
Use cases
- Invoices, purchase orders, KYC : Structured extraction with targeted human validation powered by confidence scores and layout preservation.
- Document RAG : Citation-ready, block-structured content to feed precise knowledge bases.
- Agentic workflows : Automated form and invoice processing in end-to-end AI pipelines.
- Enterprise search : Large-scale indexing of complex multilingual documents.
Customer testimonials
Several partners shared their results :
- Anaqua : Ivan Mihailov states that Mistral OCR 4 is “roughly 4x faster per page than their incumbent provider”.
- Rogo : Aidan Donohue reports reaching “equivalent accuracy at roughly 8x lower cost” compared to the parsers they benchmarked.
Why now ?
Mistral positions OCR 4 as an accelerator for AI adoption in document-heavy enterprise environments. As long as critical documents on paper and PDF remain unstructured, AI use cases (agents, analytics, automation) hit a wall at extraction. Bounding boxes and confidence scores make it possible to build more reliable pipelines, with human review reserved for low-confidence passages.
How to get started ?
- Test in Mistral Studio (PDF/Image -> text/JSON) to validate quality on your own documents.
- Prototype via the API in pure extraction mode ; enable the Batch API for high volumes (cost ÷2).
- Explore Document AI for business use cases without development using JSON schema structuring.
- Contact Mistral for self-hosting if your data privacy constraints require it.
Conclusion
With OCR 4, Mistral delivers a multilingual, multi-format OCR solution suited to enterprise document requirements. Bounding boxes, block classification, and confidence scores open the door to more precise, more controllable extraction pipelines adapted to human-in-the-loop validation workflows.
Sources
Did you enjoy this post ? If you have any questions, comments or suggestions, please feel free to send me a message from the contact form.
Don’t forget to follow us and share this post.












