Mistral Small 4, one model for reasoning, visioning, and coding
- Maxime Hiez
- Mistral AI
- 30 Apr, 2026
Introduction
Managing multiple specialized models within a single AI pipeline adds deployment complexity and multiplies infrastructure costs. Mistral AI announced on March 16, 2026 the launch of Mistral Small 4, a single model that absorbs the roles previously held by Magistral (reasoning), Pixtral (vision), and Devstral (code). For an enterprise AI admin, the message is straightforward : one API integration, three specialties covered.
Architecture and capabilities
Mistral Small 4 is built on a Mixture of Experts (MoE) architecture with 119 billion total parameters, of which approximately 6 billion are activated per token. The model uses 128 experts with 4 active simultaneously, keeping the computational footprint at inference low despite the model’s raw size.
Key characteristics :
- Context window : 256,000 tokens, sufficient to process long documents or extended conversation histories.
- Native multimodality : Text and image as input, text as output. Small 3 was strictly text-only; that limitation is gone.
- Configurable reasoning : The new reasoning_effort parameter accepts the values none or high, making it possible to switch between a fast response and deep reasoning based on the use case, without changing models.
- Language support : 24 languages including French, English, Spanish, German, Chinese, Japanese, and Arabic.
What changes compared to Small 3
The most significant difference from Mistral Small 3 is not purely about performance, it is the consolidation of several models into a single deployment point. Previously, a complete AI stack required routing requests to distinct models depending on the task, a vision model like the one introduced in Mistral OCR, a code model like Mistral Code. Small 4 eliminates that routing.
On raw performance, Mistral claims a 40% reduction in end-to-end latency and three times higher throughput in requests per second compared to Small 3. These figures are published by Mistral without a detailed methodology; they should be treated as indicative until an official technical report is available. Independent measurements by Artificial Analysis place the model at 171.8 tokens per second with a time-to-first-token (TTFT) of 0.76 seconds via the Mistral API.
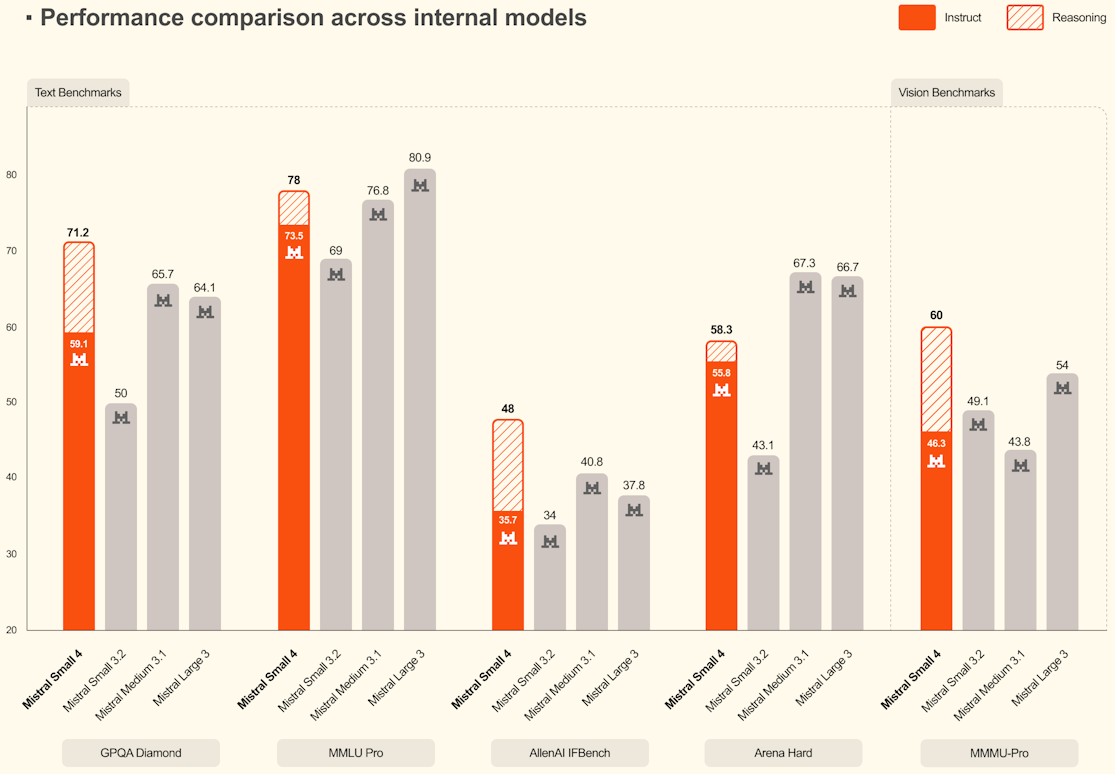
Benchmarks
In the absence of an official technical report at the time of the announcement, the results below come from secondary sources and Mistral publications. They provide a positioning indication but do not constitute a complete, independent evaluation.
| Mistral Small 4 | GPT-4o-mini | |
|---|---|---|
| GPQA Diamond | 71.2% | 40.2% |
| MMLU-Pro | 78.0% | 64.8% |
| LiveCodeBench | Outperforms GPT-OSS 120B (−20% tokens) | - |
On the AA LCR (weighted response length) benchmark, Small 4 scores 0.72 for 1,600 characters, against ranges of 5800 to 6100 characters for Qwen 3.5-122B, reflecting a notably concise output style.
Access and deployment
Mistral Small 4 is available under the Apache 2.0 license, authorizing commercial use without revenue restrictions, unlike Meta’s LLaMA conditions, which impose usage thresholds based on organization size.
Available access channels at launch:
- Mistral API and AI Studio : Pricing sourced via Artificial Analysis and OpenRouter: $0.15 per million input tokens, $0.60 per million output tokens, not yet published on the official Mistral pricing page at time of writing.
- Hugging Face : mistralai/Mistral-Small-4-119B-2603
- NVIDIA NIM, vLLM, llama.cpp, SGLang, Transformers, Axolotl (fine-tuning)
For self-hosting, the minimum hardware requirement is significant:
- 4× NVIDIA HGX H100
- 2× HGX H200
- 1× DGX B200
This level of infrastructure rules out consumer GPU deployments or lightweight on-premises setups; the API remains the most accessible option for most organizations.
Conclusion
Mistral Small 4 addresses a concrete enterprise AI stack problem, instead of maintaining three separate models for reasoning, vision, and code, a single deployment covers all three. The Apache 2.0 license, the reasoning_effort parameter, and the 256k context make it a serious candidate for diverse automation workflows. The absence of an official technical report is a reason to validate benchmarks against internal use cases before any production commitment.
Sources
Hugging Face - mistralai/Mistral-Small-4-119B-2603
Artificial Analysis - Mistral Small 4
OpenRouter - mistralai/mistral-small-2603
MindStudio - What is Mistral Small 4
Emelia - Mistral Small 4 Complete Guide
Did you enjoy this post ? If you have any questions, comments or suggestions, please feel free to send me a message from the contact form.
Don’t forget to follow us and share this post.