Mistral Small 4, un seul modèle pour raisonnement, vision et code
- Maxime Hiez
- Mistral AI
- 30 Apr, 2026
Introduction
Gérer plusieurs modèles spécialisés dans une même chaîne IA complexifie les déploiements et multiplie les coûts d’infrastructure. Mistral AI a annoncé le 16 Mars 2026 le lancement de Mistral Small 4, un modèle unique qui absorbe les rôles tenus jusqu’ici par Magistral (raisonnement), Pixtral (vision) et Devstral (code). Pour un admin IA en entreprise, le message est simple : une seule intégration API, trois spécialités couvertes.
Architecture et capacités
Mistral Small 4 repose sur une architecture Mixture of Experts (MoE) avec 119 milliards de paramètres au total, dont environ 6 milliards activés par token. Le modèle embarque 128 experts, 4 actifs simultanément, ce qui permet de maintenir une faible empreinte computationnelle à l’inférence malgré la taille brute du modèle.
Parmi les caractéristiques à retenir :
- Fenêtre de contexte : 256 000 tokens, suffisant pour traiter de longs documents ou des historiques de conversation étendus.
- Multimodalité native : Texte et image en entrée, texte en sortie. Small 3 était strictement text-only ; cette limite disparaît.
- Raisonnement configurable : Le nouveau paramètre reasoning_effort accepte les valeurs none ou high, ce qui permet de basculer entre une réponse rapide et un raisonnement approfondi selon le cas d’usage, sans changer de modèle.
- Support linguistique : 24 langues dont le Français, l’Anglais, l’Espagnol, l’Allemand, le Chinois, le Japonais et l’Arabe.
Ce qui change par rapport à Small 3
La différence la plus structurante avec Mistral Small 3 n’est pas uniquement de performance, c’est la consolidation de plusieurs modèles en un seul point de déploiement. Auparavant, une stack IA complète nécessitait de router les requêtes vers des modèles distincts selon la nature de la tâche, un modèle de vision comme celui présenté dans Mistral OCR, un modèle de code comme Mistral Code. Small 4 supprime ce routage.
Sur le plan des performances brutes, Mistral annonce une réduction de latence de 40% de bout en bout et un débit trois fois supérieur en requêtes par seconde par rapport à Small 3. Ces chiffres sont publiés par Mistral sans méthodologie détaillée disponible ; ils sont à considérer comme indicatifs jusqu’à la publication d’un rapport technique officiel. Les mesures indépendantes d’Artificial Analysis placent le modèle à 171,8 tokens par seconde avec un délai avant premier token (TTFT) de 0,76 seconde via l’API Mistral.
Benchmarks
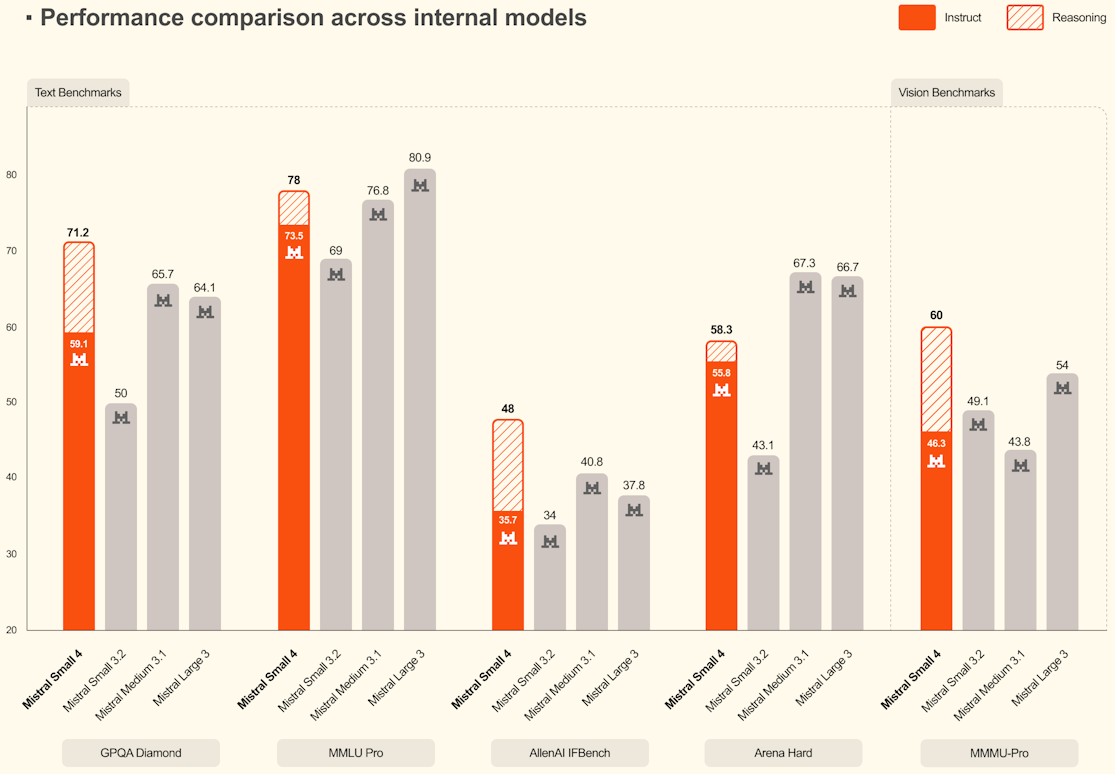
En l’absence de rapport technique officiel au moment de l’annonce, les résultats ci-dessous proviennent de sources secondaires et de publications Mistral. Ils donnent une indication de positionnement mais ne constituent pas une évaluation complète et indépendante.
| Mistral Small 4 | GPT-4o-mini | |
|---|---|---|
| GPQA Diamond | 71.2% | 40.2% |
| MMLU-Pro | 78.0% | 64.8% |
| LiveCodeBench | Surpasse GPT-OSS 120B (−20 % tokens) | - |
Sur le benchmark AA LCR (longueur de réponse pondérée), Small 4 obtient un score de 0,72 pour 1 600 caractères, contre des plages de 5 800 à 6 100 caractères pour Qwen 3.5-122B, ce qui reflète une concision marquée des réponses.
Accès et déploiement
Mistral Small 4 est disponible sous licence Apache 2.0, ce qui autorise l’usage commercial sans restriction sur les revenus, contrairement aux conditions de LLaMA de Meta, qui imposent des seuils d’utilisation selon la taille de l’organisation.
Les canaux d’accès disponibles au lancement :
- API Mistral et AI Studio (tarification relevée via Artificial Analysis et OpenRouter : 0,15$ / million de tokens en entrée, 0,60$ / million de tokens en sortie, non encore publiée sur la page officielle Mistral au moment de la rédaction)
- Hugging Face : mistralai/Mistral-Small-4-119B-2603
- NVIDIA NIM, vLLM, llama.cpp, SGLang, Transformers, Axolotl (fine-tuning)
Pour l’auto-hébergement, la configuration minimale requise est élevée :
- 4× NVIDIA HGX H100
- 2× HGX H200
- 1× DGX B200.
Ce niveau d’infrastructure exclut les déploiements sur GPU grand public ou les configurations on-prem légères ; l’API reste l’option la plus accessible pour la majorité des organisations.
Conclusion
Mistral Small 4 simplifie un problème concret de stack IA en entreprise, au lieu de maintenir trois modèles distincts pour le raisonnement, la vision et le code, un seul déploiement couvre les trois. La licence Apache 2.0, le paramètre reasoning_effort et le contexte 256k en font un candidat sérieux pour des workflows d’automatisation variés. L’absence de rapport technique officiel invite à valider les benchmarks sur les cas d’usage internes avant tout engagement en production.
Sources
Hugging Face - mistralai/Mistral-Small-4-119B-2603
Artificial Analysis - Mistral Small 4
OpenRouter - mistralai/mistral-small-2603
MindStudio - What is Mistral Small 4
Emelia - Mistral Small 4 Complete Guide
Avez-vous apprécié cet article ? Vous avez des questions, commentaires ou suggestions, n’hésitez pas à m’envoyer un message depuis le formulaire de contact.
N’oubliez pas de nous suivre et de partager cet article.