Mistral OCR 3, un OCR précis, structuré et abordable
- Maxime Hiez
- Mistral AI
- 15 Jan, 2026
Introduction
En Décembre 2025, Mistral AI a annoncé le lancement de Mistral OCR en version 3, une API de reconnaissance optique de caractères (OCR) qui établit une nouvelle norme en matière de compréhension des documents. Cette technologie avancée permet de traiter et de transcrire des documents complexes avec une précision et une rapidité inégalées, offrant ainsi des capacités de compréhension des documents à un niveau jamais atteint.
Ce qui change avec OCR 3
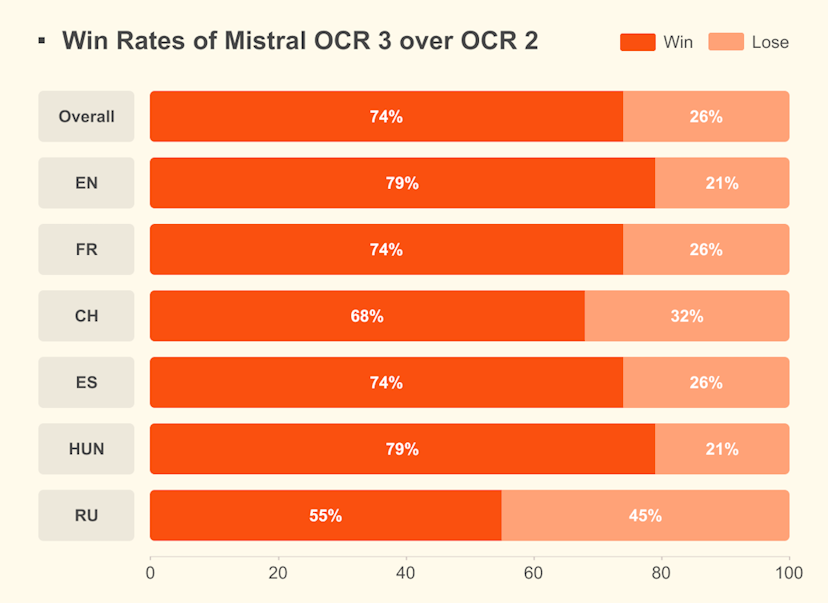
- Hausse nette de précision sur les formulaires : L’écriture manuscrite, les scans dégradés et les tableaux complexes, avec 74% d’amélioration par rapport à OCR 2 (évaluations internes sur cas métier, …).
- Sorties structurées : OCR 3 produit du Markdown qui conserve la mise en page, et reconstruit les tableaux en HTML (rowspan/colspan).
- Pensé pour l’automatisation : La réponse API inclut du JSON avec une liste de pages (markdown par page, images, liens détectés, en‑têtes/pieds optionnels), des annotations structurées.
Expérience développeur et studio
- Modèle : mistral-ocr-2512 (intégration via API publique).
- Document AI Playground dans Mistral AI Studio : Importez un PDF ou une image et récupérez du texte propre ou du JSON structuré sans coder.
- Placeholders intelligents : Le Markdown fait référence aux images / tableaux via des placeholders (![img-0.jpeg], [tbl-3.html]) résolus à partir des tableaux images / tables du JSON, cela simplifie la reconstruction fidèle du document.
Tarification et disponibilité
- Standard : 2$ / 1 000 pages
- Batch API : –50% soit 1$ / 1 000 pages
- Annotations structurées : 3$ / 1 000 pages
À ces niveaux de prix, OCR 3 bat de nombreuses solutions d’extraction documentaire d’entreprise tout en apportant une excellente qualité sur les cas complexes (formulaires + écriture manuscrite + tableaux).
Cas d’usage
- Factures, bons de commande, KYC : Extraction prêts‑à‑l’emploi de champs + validation humaine limitée grâce aux structures HTML/JSON et au maintien du layout.
- Archives et dossiers scannés : Résilience accrue aux scans dégradés ; manuscrits et annotations mieux gérés pour créer des archives recherchables ou nourrir des agents IA.
- Tableaux complexes (bancaire, santé, public) : Reconstruction HTML + Markdown facilitent l’ingestion vers des pipelines analytiques.

Pourquoi maintenant ?
Mistral positionne l’OCR comme première brique d’une stratégie IA en entreprise. Tant que les données critiques sur papier/PDF ne sont pas digitalisées et structurées, les cas d’usage IA restent confinés au POC. OCR 3 veut débloquer ces gisements de données et accélérer le passage du pilote à la production (automatisation de processus, agents, …).
Comment démarrer ?
- Tester dans le Playground (PDF/Image -> texte/JSON) pour valider la qualité sur vos documents.
- Prototyper l’API mistral-ocr-2512 ; activer la Batch API pour les volumes (coût ÷2).
- Stocker les JSON/HTML générés, brancher un post‑traitement (règles, mapping, LLM, RPA), et monitorer.
Conclusion
Avec Mistral OCR 3, on obtient un OCR de nouvelle génération : précis sur les cas complexes, structure‑aware pour l’automatisation et économique à l’échelle. Pour les organisations qui veulent ouvrir leurs données documentaires à l’IA (agents, analytics, …), c’est un accélérateur immédiat ; simple à tester, rapide à déployer, et abordable.
Sources
Avez-vous apprécié cet article ? Vous avez des questions, commentaires ou suggestions, n’hésitez pas à m’envoyer un message depuis le formulaire de contact.
N’oubliez pas de nous suivre et de partager cet article.